L'informatica semplice: cosa fa funzionare un calcolatore




- L'automazione del calcolo come basilare dell'Universo
- Le regole del pensiero e la Macchina di Turing
- Lo schema di John von Neumann
- Il Sistema Operativo
- Tipi di Sistema
- Il kernel
- Il File Manager e l’interfaccia di gestione
- Directory, file, byte e multipli
- Hard Drive e RAM
- RAM, ROM, flash e volatilità
- L'epoca del touch e le nuove interfaccie grafiche mobili
- Possiamo aiutarti?
Contattaci qui, e ti richiameremo noi!

Quest'articolo è stato aggiornato il giorno: martedì 4 febbraio, 2025
L'automazione del calcolo come basilare dell'Universo
L’informazione automatica è una delle più grandi conquiste dell’umanità.
Come la sua consorella matematica, ha facilitato enormemente l’esistenza dell’uomo in pressoché ogni aspetto della vita, tanto che ormai è per davvero impossibile trovare anche un solo settore che non si avvalga della computazione elettronica per svolgere lavoro.
Sebbene possa apparire una scienza piuttosto recente, in realtà l’informatica ha origini ben più antiche di quello che si crede: fosse altro perché le sue basi di calcolo, o meglio il suo sistema di calcolo in codice binario, è stato inventato dal grande matematico tedesco Gottfried Wilhelm von Leibniz addirittura nel 1600!

Il grande Gottfried Wilhelm von Leibniz, genio universale a tutto tondo, nonché padre del sistema binario
Ma in realtà, sin da quando l’uomo ha cominciato a far di conto, s’è sempre sentita l’esigenza di facilitare le operazioni aritmetiche d’uso comune, soprattutto nel commercio, dove grossi volumi d’affari, differenti pesi e misure, oltreché monete di scambio, rendevano (e rendono tuttora) l’automazione di tante operazioni un’esigenza ben sentita dai mercanti di ogni tempo.
La computazione automatica, se vogliamo, ha origini ancora più antiche, che risiedono… Nell’infinita varietà delle cose che compongono l’Universo.
Particelle sub-atomiche, atomi, molecole, molecole che si aggregano formando la vita, il DNA, la riproduzione cellulare, il nostro cervello: tutte operazioni automatiche, basate sulle leggi della fisica e sulle reazioni chimiche da esse derivate, che si ripropongono infinitamente, in una gigantesca equazione non lineare che noi chiamiamo ‘realtà dimensionale’.
Essere dunque parte di questo meccanismo, ed aver cominciato a comprenderlo ed usarlo per i nostri scopi, è stato ed è uno dei massimi picchi evolutivi della nostra razza. Un picco a cui s’è arrivati per gradi, per sbagli, per intuizioni, per invenzioni, per grossi fallimenti ed altrettanto grossi riscontri.
Se ora possiamo agevolmente comunicare in maniera istantanea con tutto il mondo popolato, oppure aver guadagnato molte ore di tempo libero, risparmiandole al lavoro (e a parità di opera svolta), è solamente grazie all’enorme lavoro che matematici, fisici, ingegneri, tecnici e tante altre menti assortite hanno svolto per una serie considerevole di… Millenni.
Purtroppo, ancora oggi molte persone sono restie all’uso, anzi alla conoscenza, dell’informatica; spesso, per motivi veramente risibili, quando non sciocchi.
Lo stesso discorso si applica alla matematica, che è una bellissima scienza che è erroneamente vista come ‘ostica’, quando invece è totalmente l’opposto.
Matematica e derivata consorella informatica non sono state inventate per complicarci la vita, tutt’altro: sono state inventate per facilitarcela, e di molto!
Se quindi avete remore e/o reticenze varie nei confronti dell’informatica, è perché avete avuto un cattivo insegnamento nel passato, che ha creato lacune ed infondati blocchi logici che debbono essere superati.
Questo articolo, lungi dall’essere un testo onnicomprensivo, vuol solo darvi un’idea generale di com’è un calcolatore moderno, cosa lo fa funzionare e com’è strutturato.
Per sperare che la cosa vi sia gradita e, laddove lo desideriate, possiate approfondire la conoscenza con una delle scienze più affascinanti di tutto lo scibile umano.
Buona lettura.
NOTA: In quest'articolo parleremo quasi esclusivamente della parte software del calcolo elettronico.
Per sapere come sia fisicamente possibile che un pezzo di silicio, opportunamente trattato, riesca ad eseguire calcoli complessi, potete leggere quest'altro articolo.
Le regole del pensiero e la Macchina di Turing

Il grande George Boole, il padre della logica matematica
Nel 1854, un gentile signore chiamato George Boole pubblica un libro particolare, dal titolo affascinante e dai contenuti ancora più affascinanti: “An investigation of the laws of thought” (un esame sulle regole del pensiero, in italiano).
Nel succo, tutto il libro convergeva su un punto critico: il pensiero umano, spogliato dalle sue verbosità e ridotto ai minimi termini (letteralmente) non era altro che un insieme sequenziale di scelte.
Secondo Boole, qualsiasi processo logico poteva essere ricondotto ad una sequenza di eventi elementari, non ambigui e dalla sintassi definita: tutto ciò prende il nome di algoritmo.
Che ci crediate o no, tutta l’informatica per come noi la conosciamo si regge su questa parola.

Il grande Alan Turing, che con la sua intuizione aprì la strada al concetto di 'calcolatore automatico' per come noi lo conosciamo.
Genio indiscusso del 1900, il suo automa deterministico, la famosa Macchida di Turing, è il fondamento del calcolo elettronico,
e tutti i nostri smartphone, tablet, computer generici odierrni, non ne sono che l'implementazione fisica.
Dalla vita tormentata, il geniale Alan morì a soli 41 anni, suicida dopo che l'allora Governo britannico lo perseguitò in maniera orripilante per via della sua omosessualità.
Al padre del calcolo automatico, è stato dedicato nel 2014 il film "The Imitation Game"
Nel 1932, un giovane matematico inglese chiamato Alan Turing, ragionando sulle regole del pensiero proposte da Boole, ideò un automa, o macchina che dir si voglia, dal concetto unico: l’automazione del calcolo. Secondo lo schema di Turing, tale automa era composto solo da due componenti:
- Una testina mobile di calcolo, che eseguiva materialmente le operazioni di lettura / scrittura;
- Una bobina di carta divisa in tanti quadrati eguali, di lunghezza infinita, sulla quale la testina poteva muoversi liberamente
È bene precisare che Turing non costruì mai, fisicamente, una macchina del genere: sarebbe stato impossibile farlo, all’epoca (ed anche ora, a ben vedere), e sarebbe stato anche decisamente inutile.
Perché inutile? Perché la Macchina di Turing è un automa ideale: serve a dare l’idea, il concetto, la fattibilità logica. Non è quindi necessario che venga materialmente costruito, così come non è necessario diventare materialmente ricchi, per fantasticare sui nostri progetti da nababbi.
Alan Turing forse ancora non lo sapeva, ma il suo concetto d’automa si rivelò una grandissima intuizione, e spianò la strada, di fatto, all’implementazione fisica di un semplice, eppur così efficace, processo logico.
Tutti i calcolatori moderni (tutti, nessuno escluso), che siano smartphone, tablet, desktop, laptop, server o mainframe aziendali, sono riconducibili allo schema primordiale dell’automa di Turing. Col tempo, la testina di calcolo ipotizzata dal geniale matematico inglese s’è trasformata nel processore, e la bobina divisa in tanti quadrati eguali… Beh, forse ci arrivate da soli: è la memoria.
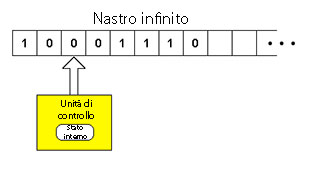
Un semplice schema dell'automa di Turing: il nastro infinito può essere considerato come una memoria, l'unità di controllo come una moderna CPU,
con lo stato interno oggi rappresentato dai registri
Lo schema di John von Neumann

Il grande John von Neumann, che ideò l'architettura hardware necessaria per la messa in pratica
dell'automa di Alan Turing. Tale architettura, tutt'ora nel 2015, è la base universale per qualsiasi
tipo di calcolatore, a prescindere da CPU e Sistema Operativo usato
Nel 1936, quasi in contemporanea con il progetto del primo automa ideato da Alan Turing, un ungherese naturalizzato poi statunitense nomato John von Neumann mise a punto uno schema generale per l’architettura di una ipotetica macchina da calcolo non ideale come quella di Turing, ma bensì un vero e proprio progetto d’ingegneria per rendere l’automa del grande matematico inglese fisicamente operativo.
Il progetto prevedeva la definizione di un’architettura specifica, ovviamente in accordo con i ritrovati tecnologici all’epoca disponibili. Al tempo nessuno mai avrebbe potuto prevedere che l’architettura progettata dall’ungherese potesse essere così vincente, al punto tale da divenire (con poche o nulle modifiche) lo standard basilare per la costruzione di più o meno tutti i calcolatori prodotti industrialmente negli anni a venire.
Questo standard progettuale è valido sino ai giorni nostri, giacché praticamente tutti i calcolatori esistenti e prodotti su larga scala (con pochissime variazioni) sono costruiti con lo schema concettuale che il grande matematico ungherese progettò tanti anni fa. Questo schema è conosciuto proprio come schema della Macchina di von Neumann, ed è un’architettura di base a tutti i calcolatori moderni.
Lo schema è semplice, ed è spiegato in dettaglio nel grafico dabbasso:
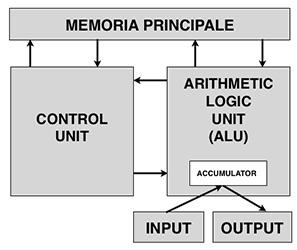
Lo schema generale dell'architettura di von Neumann.
Salvo pochissime differenze (più a livello di implementazione, che concettuale), tale schema è tutt'ora valido ed usato
in tutti i calcolatori automatici esistenti
Nello specifico, l’unità ALU è il circuito che costituisce il core della CPU: come il nome suggerisce (Unità Logica e Aritmetica), il suo compito è quello di eseguire mere operazioni aritmetiche.
Nelle moderne CPU, ci possono essere più ALU, di calcolo generico oppure per un’operazione specifica (esempio: estrazione della radice quadrata), lavoranti in parallelo, che aumentano di molto il numero massimo di operazioni per ciclo.
L’accumulatore, ora chiamato registro della CPU, non è niente altro che la memoria interna alla CPU, che l’ALU utilizza come banco di lavoro: tutte le operazioni che l’ALU esegue, sono eseguite nei registri.
La Control Unit, ovvero l’unità di controllo, è quella parte della CPU che si occupa fisicamente di prendere istruzioni dalla memoria e riversare dati elaborati dall’ALU in essa. Tutti questi componenti formano quello che è chiamato processore di calcolo, quindi la CPU (acronimo inglese Central Processing Unit).
La memoria principale è il secondo elemento indispensabile dell’automa di Turing, e ha lo scopo di conservare le informazioni per un certo periodo di tempo.
Più specificatamente, in buona sostanza l’operatore immette dati da elaborare nella memoria, carica le istruzioni ed attende che la CPU elabori il tutto.
Al temine del calcolo, nella memoria saranno presenti i dati elaborati.

Nello schema di von Neumann, le unità di memoria di massa come hard drive e CD/DVD sono viste come generiche periferiche I/O.
Questo perché, all'epoca del grande fisico ungherese, tali tipi di memorie non erano neppure lontanamente immaginabili
Come si può facilmente notare, nello schema classico originario progettato da von Neumann mancano dei componenti che invece oggi ritroviamo in ogni calcolatore: le memorie di massa (dischi rigidi, drive esterni, memorie e schede flash, ecc ecc, anche CD-ROM e DVD).
Come mai? È semplice: ai tempi, quando von Neumann ideò questa particolare architettura, memorie di massa ad accesso sequenziale come HDD, SSD e compagnia bella, erano difficilmente immaginabili, anche per una mente vivida come quella del grande pioniere dell’informatica.
Con l’avanzare della tecnologia però, implementare tali memorie si rese possibile, anzi obbligatorio, e quindi furono incorporate nell’architettura originaria come dispositivi generici di I/O (input/output).
Tutt’ora, un generico File di Sistema per una generica CPU tratta hard drive e unità flash USB (e anche qualsiasi supporto ottico) come un dispositivo I/O.
Un retaggio di un’epoca passata, ma fondamentale, che ancora ci portiamo appresso.
Il Sistema Operativo
Una schermata iconica dell'informatica degli anni '80: il famoso MS-DOS, uno dei primi Sistemi Operativi ad avere un altissimo grado di penetrazione nelle utenze professionali ed amatoriali, e che resò lo standard de facto per molti settori dell'informatica fino all'avvento delle interfacce GUI, nella prima metà degli anni '90
Agli albori della progettazione informatica, quando le porte logiche di una CPU erano grandi fino ad un metro (sul serio!) e tutto un calcolatore completo poteva benissimo occupare un intero piano di un palazzo (il famoso ENIAC, ad esempio), gli ingegneri ed i matematici che si occupavano di procedere con le sperimentazioni adottavano un sistema molto spiccio per caricare le istruzioni nel calcolatore: le inviavano manualmente in memoria, su vari supporti (principalmente, schede forate). I programmi quindi venivano caricati uno per uno, e la primitiva CPU poteva quindi eseguire una sola istruzione, oppure set di istruzioni, per volta.
Come si direbbe adesso, tutti gli enormi calcolatori dell’epoca erano mono-tasking, ovvero potevano eseguire un applicativo (task) per volta.
Quando il programma era in esecuzione, esso aveva il controllo completo della CPU, rendendo impossibile caricare altri programmi in memoria.
Questo generava dei problemi, a volte seri.
Ad esempio: poteva succedere che un particolare set di istruzioni di un programma richiedeva un calcolo rapido alla CPU; questa lo eseguiva rapidamente, ma il ritorno dei dati elaborati in memoria era fisicamente molto più lento di una decina di calcoli di eguale tempo d’esecuzione.
Il calcolatore quindi perdeva molto tempo inutilmente: la CPU era libera da compiti ed avrebbe potuto anche eseguire un altro set d’istruzioni, ma il tutto era bloccato dalla lentezza del riversamento in memoria.
Per svuotare la memoria dalle istruzioni date, i tecnici molto semplicemente spegnevano tutta la macchina, il che causava la dispersione delle informazioni caricate nei condensatori della memoria. Un po’ scomodo, in effetti, ma all’epoca non si poteva davvero pretendere di più.
Con l’avvento dei transistor, dell’effetto transistor, della miniaturizzazione dei componenti dei calcolatori e dell’aumento esponenziale della potenza di calcolo, ci si accorse sempre di più che c’era una differenza ben precisa tra la velocità d’esecuzione di una CPU ed il mero output dei dati.
Una differenza considerevole, che generava sempre inutili tempi morti e, di fatto, era un freno a mano costantemente tirato a scapito del processore.
Si cominciò così ad ideare un sistema per sincronizzare i tempi, anzi, per ottimizzare le istruzioni di input e l’output elaborato. L’idea di un programma che gestisse automaticamente più programmi, quindi, finì per essere considerata fattibile.
I primi Sistemi Operativi, abbreviati comunemente in OS (Operating System), nacquero proprio con questa esigenza: ottimizzare i tempi morti della CPU. Col tempo, anzi con i decenni, sono stati prodotti innumerevoli OS, per pressoché tutti i processori prodotti, sia di largo consumo che specifici.
Allo stato attuale un generico Sistema Operativo è un software estremamente complesso, ricchissimo di funzioni che ha un solo ed unico compito: permettere all’utente di interfacciarsi con la macchina. Più semplicemente, efficientemente e velocemente possibile.
Sono a disposizione degli utenti moltissimi OS, per tutti i gusti, che gestiscono tantissime macchine, di hardware diverso e variegato, per scopi altrettanto diversi e variegati.
Tipi di Sistema
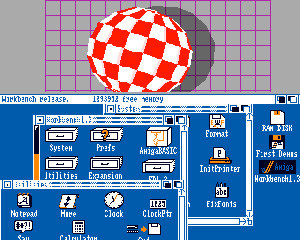
Il celebre Amiga OS, nella sua prima versione degli anni '80.
Fu il primo Sistema Operativo per le grandi utenze ad essere totalmente in multitasking preempitivo.
Era un multitasking talmente avanzato all'epoca che, idea poi ripresa da altri OS solo decenni dopo, poteva visualizzare contemporaneamente differenti scrivanie, ognuna con applicativi e preferenze scelte dall'utente, che giravano in background
Una prima differenziazione tra i tanti OS prodotti nel corso degli anni si può ottenere prestando attenzione a quanti task (quindi, applicativi) un dato Sistema è capace di gestire contemporaneamente.
Un OS si dice monotasking quando può eseguire solamente un programma alla volta, mentre è multitasking quando, al contrario, può gestire differenti programmi in contemporanea.
Allo stato attuale della tecnologia, praticamente tutti gli OS esistenti sono multitasking.
Ancora, gli OS multitasking si differenziano tra di loro sul come riescono a gestire i differenti programmi.
I modi sono essenzialemente due:
- Multitasking cooperativo (senza prelazione);
- Multitasking preempitivo (con prelazione)
Il multitasking cooperativo è stato uno dei primi ad essere implementato per le masse (il Mac OS, fino alla versione 9, ne faceva uso), ma ormai è totalmente in disuso. In esso, quando viene lanciato in memoria un programma, esso acquista il totale controllo della macchina, e lo cede nuovamente al Sistema quando invece ha finito l'esecuzione delle istruzioni.
Si tratta di una procedura molto snella e veloce, che può essere adattata a pressoché qualsiasi processore e che non necessita di alcun supporto hardware esterno, però ha il grande svantaggio di risultare pericoloso: se infatti un dato programma si rifiuta di cedere nuovamente il controllo al Sistema, si ha il blocco totale di esso.
Questo perché il Sistema non ha alcun modo di riprendere il controllo da solo. A riguardo, ne sanno bene qualcosa i vecchi utenti del Mac OS originario, con l'orribile icona della bomba...
Il multitasking con prelazione, invece, è in grado di forzare il Sistema a riprendere il controllo a prescindere dal rilascio dello stesso da parte dell'applicativo: questo perché si avvale di specifici supporti hardware (integrati nel processore), che entrano in funzione autonomamente in caso di errori logici, e permettono quindi al Sistema un controllo pressochétotale degli applicativi in esecuzione.
Questo multitasking quindi ha il grandissimo vantaggio di salvaguardare il Sistema stesso in caso di crash di un applicativo, ma necessita di particolare supporto hardware.
Nel corso degli anni, gradualmente tutti gli OS più popolari ed usati sono passati al multitasking con prelazione.
Il kernel
Un generico Sistema Operativo può essere visto, in estrema sintesi, come un enorme software composto da più parti distinte, che regolano differenti funzioni e proprietà ma che, dall'esterno, appaiono un'unica entità all'utilizzatore.
Si tratta quindi di un concetto modulare e, in effetti, un qualsiasi OS è un insieme di molti moduli, basilari o non, che ne determinano, nel complesso, le caratteristiche generali.
Tutte le componenti del Sistema, hanno come unica funzione finale sempre il controllo dell'utente sul calcolatore.
Nel corso dei decenni, ai moduli base di Sistema, progettati per primi dagli ingegneri dell'epoca (uno dei primissimi, a tal riguardo, fu proprio il modulo capace di coordinare la stampa dei dati), se ne sono aggiunti tanti altri, fino ad ottenere Sistemi dalle molteplici funzioni e caratteristiche che tutti noi oggi usiamo.
Tra i tanti, il modulo essenziale di un qualsiasi Sistema è però il kernel.
È una parte talmente essenziale da essere considerata il cuore di ogni OS, senza di cui non sarebbe proprio possibile parlare di 'Sistema'.
Il kernel, in sostanza, esegue una sola funzione, ma basilare: fornisce l'accesso sicuro e protetto dei processi attivi alle risorse hardware (in primis, la memoria).
Qualsiasi programma in esecuzione è autorizzato ad usare qualsiasi componente hardware del calcolatore sul quale opera se e solo se il kernel da il via libera; in caso contrario, il processo si mette in coda ed attende il suo turno.
Questo è fondamentale, perché così facendo il kernel assicura sempre che non vi siano istruzioni in conflitto tra di loro, nell'usare la stessa risorsa.
La programmazione del kernel è così importante che, in base a come è progettato, un dato Sistema Operativo rientra in una data famiglia, e può essere quindi anch'esso fonte di catalogazione nella miriade dei Sistemi finora prodotti.
In base dunque a come è compilato un dato kernel, possiamo avere:
- Kernel monolitici
Sono kernel in cui tutte le funzioni sono integrate strettamente tra di loro, e possono quindi essere visti appunto come un 'blocco intero', totalmente collegato in ogni sua parte.
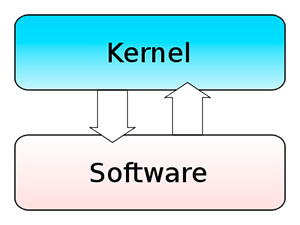
Una schematizzazione di un generico kernel monolitico. Tutti i servizi del kernel sono programmati in un unico blocco, e sono totalmente integrati tra di loro. Il kernel quindi si interfaccia al software come se, per l'appunto, fosse un monolite unico.
Se programmato bene, è il kernel che offre le massime prestazioni e la massima stabilità
Dal punto di vista prestazionale, se programmati bene, sono i kernel che danno la stabilità e le prestazioni migliori in assoluto; il contro della medaglia è che la programmazione deve essere per l'appunto esente il più possibile da errori, datosi che anche il più piccolo difetto di un componente può ripercuotersi su tutto il restante codice.
Ancora, per via della loro interconnessione totale tra tutte le parti che lo compongono, un kernel monolitico da modificare (anche una riga di codice) richiede la ricompilazione di tutto il programma.
Sono esempi di kernel monolitico puro: UNIX, Linux
- Microkernel
Kernel
totalmente opposti a quelli monolitici: qui la struttura fondamentale del kernel è ridotta all'osso, e tutte le componenti aggiuntive sono programmate in livelli distaccati (a livello di pura progettazione), interconessi tra di loro.
In pratica, è un modulo software composto da altri sotto-moduli, facenti capo ad una base comune.
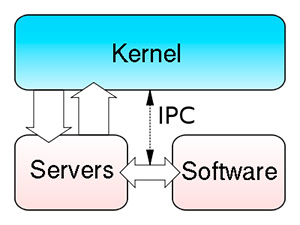
La schematizzazione di un generico microkernel: la struttura principale è ridotta ai minimi termini, e tutti i servizi del kernel sono programmati come se fossero esterni ad essa. La comodità è che la programmazione può essere modificata molto più semplicemente rispetto ad un kernel monolitico, e che servizi aggiuntivi possono essere implementati abbastanza rapidamente, senza stravolgere la struttura di base
Per la loro estrema sintesi e snellezza, sono kernel che, di solito, sono capaci di struttare al meglio hardware non troppo potenti.
Sono esempi di microkernel: Minix, BeOS
- Kernel ibridi
Sono kernel che, come il nome lascia intuire, sono a metà strada tra un kernel monolitico puro ed un microkernel.
Nello specifico, del kernel monolitico prendono la struttura di base d'interconnessione totale, ma integrano tutti i servizi in sotto-sezioni ben divise, sebbene comunque parte del blocco unico di base.
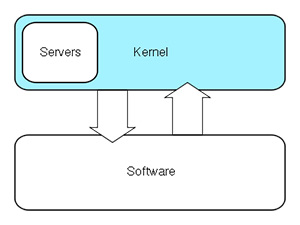
La schematizzazione di un kernel ibrido: la struttura monolitica incorpora i servizi aggiuntivi, integrati alla stessa ma virtualmente indipendenti da essa.
Si tratta di un kernel che prende il meglio dai monolitici puri, incorporando la snellezza dei microkernel. Attualmente, è la tipologia di kernel più usata in pressoché tutti gli ambiti dell'informatica contemporanea
Quest'accortezza permette di sfruttare al meglio i vantaggi della grande stabilità della struttura monolitica, sfruttando però la snellezza di programmazione e la grande facilità di modifiche singole ai sotto-moduli che garantisce un microkernel.
Tutti gli OS più usati al momento hanno una struttura ibrida.
Sono esempi di kernel ibrido: Microsoft Windows, OS X
Per i Sistemi mobili, Google Android, essendo derivato dal kernel di Linux, a sua volta possiede un kernel monolitico, e iOS, essendo derivato da OS X, vede il suo kernel come ibrido.
Il File Manager e l’interfaccia di gestione
Un classico esempio di File Manager grafico: il Finder di OS X, erede a sua volta dello storico Finder del Mac OS Classic
Molto tempo fa, quando un comune Personal Computer era presente in (forse) una famiglia su cento, in tutto l’occidente, i Sistemi Operativi permettevano di controllare la macchina quasi esclusivamente tramite un’interfaccia testuale.
Erano i tempi della prima ondata di informatica per le masse, e Bill Gates aveva già creato una piccola fortuna sviluppando per IBM un Sistema Operativo molto solido e, all’epoca, a basso costo e di facile utilizzo: il famoso MS-DOS.
Ai tempi, il massimo dell’interrelazione uomo-macchina disponibile al popolo era una scialba riga di testo, che doveva essere controllata tramite l’immissione di comandi dalla sintassi precisa.
Questo metodo di gestione del Sistema rimarrà un punto fermo per molti anni, fino all’avvento delle interfacce grafiche. Nel 1984, Steve Jobs presenta al pubblico il primo computer della nuova linea Macintosh: l’interfaccia di comando era fatta di icone ed immagini al posto del solo testo, rendendo la gestione dei documenti e della macchina in generale molto più semplice, per un utente.
Un anno dopo, alla presenza addirittura di Andy Warhol, la compianta Commodore presentò il primo calcolatore della serie Amiga, l'Amiga 1000, con precaricato il Sistema Amiga OS, anch'esso totalmente con interfaccia grafica e dotato già di multitasking con prelazione.

L'Amiga 1000, sul cui monitor si può riconoscere il primo OS totalmente grafico, a colori, della storia: l'Amiga OS.
Sebbene uscito un anno dopo la presentazione del primo Macintosh, Amiga OS e l'Amiga 1000 erano enormemente più avanzati della macchina della Apple e, per tutti gli anni '80, Amiga rimarrà la piattaforma privilegiata per grafica, musica e montaggio video professionale
L'epoca delle GUI (Graphic User Interface, ovverosia interfaccia grafica per l'utente) era appena cominciata. Tale soluzione concettuale, vincente, diventerà negli anni lo standard mondiale, fino a soppiantare del tutto la gestione a linea di comando (almeno, in ambito domestico).
Ogni GUI visualizza moduli del Sistema, preferenze, documenti e spazi dei documenti sotto forma grafica; questo ne rende la navigazione agevolata perché, ancestralmente, l’essere umano ricorda meglio le immagini rispetto ai caratteri alfanumerici.
Il modulo di ogni OS che permette la navigazione tra le informazioni caricate sul calcolatore, si chiama File Manager.
File Manager, GUI e File System permettono all’utente di interagire fisicamente con le informazioni da elaborare, oppure già elaborate, presenti nella memoria del calcolatore.
Directory, file, byte e multipli
Una tipica linea di comando del MS-DOS.
In tale OS, tutte le directory sono riconoscibili dall'indicativo <DIR>
Un file, oppure documento od archivio in lingua italiana, è una parte di memoria che contiene delle informazioni.
Tali informazioni sono scritte digitalmente su un supporto (di qualsiasi natura), e possono essere richiamate a piacimento dall’utente (o dal Sistema Operativo).
Un file non ha di per sé né forma fisica e né dimensione standard: il suo stato fisico e la sua dimensione cambiano a seconda di quante informazioni contiene, che tipo di informazioni contiene e come il File System decide di archiviare tali informazioni sul supporto di memorizzazione.
Benché non sia necessariamente un singolo elemento fisico (parti del file possono essere scritte dal File System su più parti di un supporto, non obbligatoriamente contigue), solitamente è visto come un singolo elemento logico dall’utente.
A livello di dimensioni, si usa quantificare i file tramite una sequenza di byte, e dei suoi multipli (secondo lo standard del SI).
Un byte, per convenzione, equivale ad otto bit (e difatti, è chiamato anche ottetto).
Un bit è la più piccola parte dell'informazione possibile, ed equivale ad una singola variabile: 0 od 1.
Due valori necessari e sufficienti per esprimere, accorpati in sequenza, qualsiasi genere di informazione, grazie al codice binario.
Va da sè che un byte, la cui sigla nel SI è la B (maiuscola) è esattamente 28, ovvero 256 possibili valori (numericamente, da 0 a 255, poiché anche lo 0 è un valore).
Sempre in sistema binario quindi, un kilobyte, appreviato in KB, è 210, un megabyte (MB) è 220, un gigabyte è 230 e via discorrendo.
Purtroppo però, come molti altri settori della vita, anche in informatica, in passato, l'evoluzione portata avanti da differenti gruppi di scienziati e programmatori, sparsi in tutto il globo e che difficilmente si coordinavano (anche per oggettive difficoltà logistiche in tempi in cui l'Internet non esisteva), ha causato diversi problemi sull'effettiva misura dei multipli del byte.
Per un fortuito caso, infatti, 210 (quindi 1 KB) risulta essere esattamente 1024 byte, ovvero una cifra molto simile a quella che si otterrebbe se si usasse il puro sistema metrico decimale del SI, che vorrebbe tutti i multipli di una data unità moltiplicati sempre su base 10.
Quindi, secondo il SI, un kilobyte dovrebbe essere 103, quindi 1000 byte.
Questo è corretto secondo lo standard del SI, ma è improponibile per un calcolatore, che invece lavora le informazioni su base non decimale, ma binaria.
Il margine di errore quindi, tra potenze decimali e binarie, è del 2,4% per il kilobyte, ma sale esponenzialmente al salire della quantità.
Più aumentano i byte necessari a stoccare le informazioni del file, più aumenta consequenzialmente il margine di errore.
Col tempo e per evitare quindi confusioni tra gli utenti, il SI ha provato a cambiare i nomi per i multipli su base binaria, per differenziarli da quelli a base decimale ma, un po' complice l'assurdità dei nuovi nomi (kibibyte, mebibyte, gibibyte ecc ecc) e un po' complice la riluttanza della gente, che nel corso degli anni s'è adeguata ai nomi standard, l'impresa è da considerarsi vana.
Tutt'ora, quindi, si continuano ad usare i vecchi nomi, sia per le misura su base decimale che binaria (in questo caso, essendo a conoscenza del margine d'errore).
Questa confusione, specie per i non esperti, è correntemente sfruttata dai produttori di memorie che indicano sui loro prodotti correttissime dimensioni calcolate su base decimale (come il SI vuole) col vecchio nome però in base binaria, innescando così volontari errori di calcolo in modo da far apparire le dimensioni effettive dei prodottipiù capienti di quello che, in effetti, sono.
Tutto legale e rispettoso dei dettami del SI, ma ben poco trasparente, per un utente non avvezzo.
I file, di qualsiasi dimensione, riesidono in una parte della memoria ma, per facilitarne la gestione da parte dell'utente, tale parte di memoria può essere 'indicizzata' a livello logico, in modo da far risultare diverse parti di essa, anche non contigue, come un unica porzione.
Una directory, oppure folder (o cartella, in italiano) è infatti un’entità puramente logica, che determina uno spazio ben preciso su un dato supporto.
Essa è indispensabile per creare strutture gerarchiche in un qualsiasi File System, datosi che una directory può contenere, a cascata ed in quantità indefinita, altre directory e/o file di varia natura.
Risulta insostituibile per tenere ordinate le informazioni in una data memoria, ed applicare permessi e classi.
Una directory presente dentro un’altra directory si chiama sub-directory, o sotto-cartella in italiano.
Creata ex novo, una qualsiasi directory ha dimensione di 0 byte. Questo, perché non è un’informazione fisica, ma è solo una sorgente, uno spazio logico che può al massimo contenere la posizione di altre informazioni.
Prima dell’avvento dei Sistemi con GUI, le directory erano indicate in molti OS con l’abbreviativo <DIR>, dir oppure semplicemente col nome proprio della directory.
Con l’introduzione delle interfacce grafiche, la directory viene associata all’icona di una cartella porta documenti (folder), oppure (più raramente) di un cassetto da scrivania.
Hard Drive e RAM

Due tipici banchi di memoria RAM, e nello specifico RAM DDR3 SO-DIMM
Componente essenziale nell'automa di Turing, assieme al processore di calcolo, è la memoria.
Per informatica, si intende 'memoria' qualsiasi supporto atto a contenere informazioni per un dato periodo di tempo; tale requisito, ovvero la durata delle informazioni (a prescindere dall'effettivo tempo trascorso dalla loro registrazione) è essenziale per l'esecuzione di qualsivoglia calcolo.
Nello schema di von Neumann, troviamo due tipi di memoria, entrambi fondamentali: la memoria principale e un la memoria accumulatore, oggigiorno chiamata semplicemente registro della CPU.
Sebbene siano entrambe memorie, hanno prelazioni differenti d'accesso: la CPU che deve materialmente eseguire i calcoli, adopererà in primis lo spazio dei suoi registri, e poi riverserà le informazioni elaborate nella memoria principale.
Si può quindi ben dire che un registro della CPU sia un po' come un banco di lavoro per il processore, che poi riverserà l'output nella memoria principale.
Al giorno d'oggi, per velocizzare ancora di più certi calcoli (soprattutto, operazioni che la CPU esegue spesso, di eguale valore e misura), è implementata direttamente nel processore un altro tipo di memoria, ovvero la memoria di cache.
Su tale memoria l'ALU della CPU salverà le operazioni ridondanti e le andrà poi a cercare quando esse si debbono ripetere.
Fondamento della memoria cache è la velocità di richiamo delle informazioni, veramente alta, e la temporaneità delle stesse: non c'è nessuna garanzia che le informazioni richiamate dall'ALU siano ancora presenti nella cache, ma vale comunque fare un tentativo.
Datosi che è una tecnologia che ha aumentato di molto il numero totale di operazioni per ciclo delle CPU, al giorno d'oggi troviamo processori financo con quattro memorie di cache (L1, L2, L3, L4), per contenere sempre più operazioni comuni da richiamare in caso di necessità.
A livello gerarchico, questa è la scala di accesso delle memorie per una generica CPU:
Registri > cache L1 > cache L2 > cache L3 > memoria principale RAM > memoria di massa
Come è facile notare, la gerarchia che segue la CPU è direttamente proprozionale alla velocità della memoria: hanno la più alta prelazione d'accesso le memorie più veloci (i registri), mentre l'ultimo posto è occupato dalle memorie più lente (le memorie di massa).
Hard Disk Drive (oppure semplicemente Hard Disk, o HDD o, in italiano disco rigido) è la memoria di massa ad accesso sequenziale dove un generico calcolatore archivia le informazioni che devono essere salvate anche a flusso elettronico interrotto.
Non sono quindi memorie volatili, in quanto i dati memorizzati rimangono tali in maniera indefinita, per il tempo voluto dall’utente (o dal Sistema, o da entrambi, a seconda dei casi).
Un’ottima introduzione alle memorie di massa potete trovarla cliccando su questo link.
Per loro stessa costruzione, le memorie ad accesso sequenziale sono molto più lente di quelle ad accesso casuale, e quindi vengono preferite quest’ultime come memoria principale.
Una memoria di tipo RAM (Random Access Memory - memoria ad accesso casuale) è attualmente implementata, come memoria principale, in tutte le architetture hardware moderne.
Sono memorie molto veloci, in quanto le celle che le compongono, oltre ad avere un accesso casuale, vedono gli indirizzi assegnati logicamente, e non fisicamente.
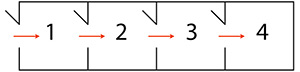
Schema di una memoria ad accesso sequenziale: le celle d'informazione hanno tempi di accesso differenti, a seconda della loro posizione.
È un tipo di memoria lento, ma che compensa la lentezza con la capacità di stoccare grandi quantità di dati in relativamente poco spazio
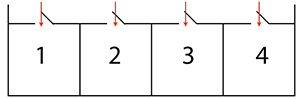
Schema di una memoria ad accesso casuale: tutte le celle d'informazione hanno tempi di accesso eguali, indipendentemente dalla loro posizione fisica.
Gli indirizzi assegnati sono logici, e pertanto è una memoria estremamente veloce.
Gli svantaggi sono un costo elevato, rispetto ad un'equivalente memoria ad accesso sequenziale, e l'impossibilità di comprimere di molto la densità delle celle, nel processo costruttivo
RAM, ROM, flash e volatilità

Delle unità a stato solido (SSD - Solid State Drive) da 2,5".
Negli ultimi dieci anni, tale tecnologia, a memoria flash, ha soppiantato quasi totalmente, almeno come unità di avvio dei Sistemi, quella magneto-meccanica tradizionale, relegata ora allo stoccaggio di grandi quantità di dati
Abbiamo già accennato che la memoria RAM, usata come memoria principale, è nella stragrande maggioranza dei casi volatile, almeno sino a questo punto dello sviluppo tecnologico.
Volatilità, in informatica, è il conservare le informazioni per un certo periodo di tempo, che comunque non è indeterminato.
Questo vuol dire che ogni volta che spegnete il vostro calcolatore, il contenuto della RAM andrà perso, definitivamente. Ciò è imputabile al fatto degli ancora grossi limiti tecnologici legati alle memorie al silicio: conservare le informazioni in questi tipo di memorie è instabile, rischioso e, industrialmente parlando, molto costoso.
Già il realizzare una comune memoria RAM (quindi ad accesso casuale) è costoso, il renderla anche non volatile non è un processo economicamente sostenibile da nessuna industria, almeno per ora.
Si sta lavorando sullʼutilizzo di memorie a cambiamento di stato per costruire le nuove RAM del futuro, che consentirebbero di salvare le informazioni anche a calcolatore spento grazie al cambio di stato molecolare, ma è una tecnologia ancora tutta da sperimentare e dai costi attualmente proibitivi.
Un caso però abbastanza comune di memorie al silicio non volatili ed a basso costo che tutti noi attualmente usiamo sono le memorie a tecnologia flash, che costituiscono tutte le nostre “penne USB”, le memorie di massa dei nostri lettori MP3, tablet e smartphone presenti sul mercato, noché tutte le schede di memoria per le nostre fotocamere.

Vari tipi di schede di memoria a tecnologia flash: dal formato CompactFlash, principalmente utilizzato per le fotocamere professionali, all'universale SD, passando anche per il formato preferito da tablet e smartphone, ovvero il Micro SD.
Grazie al crollo dei costi di produzione di tali memorie, la fotografia e la videoripresa digitale amatoriale hanno raggiunto il picco massimo di utilizzo, negli anni 2000
Sono memorie molto ingegnose, abbastanza veloci in lettura, che sfruttano la giunzione P-N alla sua estrema potenza, grazie ai diodi capaci di generare un fortissimo effetto tunnel, che rende la loro dimensione contenuta e i loro consumi elettrici modesti.
Sono memorie essenzialmente divise in celle al silicio, drogato opportunamente tanto che ogni cella è praticamente divisa in due gate, atomicamente ben distinti: il Floating Gate (FG) ed il Control Gate (CG). Il drogaggio è talmente esasperato che tutto il Floating Gate è completamente isolato in uno stato di ossido, impenetrabile dagli elettroni, che quando gli passano sopra (in grandi quantità) non hanno più energia per uscirne, e rimangono intrappolati.
Tuttavia, per far sfondare agli elettroni il muro dellʼossido occorre loro fornirgli tensione giusta, e soprattutto occorre che il flusso elettronico sia veramente cospicuo. È possibile quindi usare gli elettroni intrappolati come unità dʼinformazione (bit).
Questa “iniezione di elettroni” si ottiene applicando la giusta tensione al Control Gate... in pratica è come “flashare” il gate con una botta di tensione fortissima, di modo da iniettare elettroni: da qui il nome della tecnologia flash.
Gli elettroni intrappolati nel FG ovviamente modificano in minima parte la conduttività del gate, e quindi quando una corrente alla giusta tensione gli passa sopra, essa scorrerà in maniera non omogenea, a seconda della resistenza elettrica che incontrerà nelle zone di eccedenza di elettroni intrappolati o meno.
Questa differenza di conduttività, in fase di lettura della memoria, è vista come uno dei due valori logici 0 e 1: quindi, il bit viene letto.
Questo permette di conservare, scrivere e leggere le informazioni di una memoria flash.
Quando invece di devono cancellare le informazioni, si sfrutta lʼeffetto tunnel, ma stavolta allʼinverso: applicando una differenza di tensione al CG, si estraggono gli elettroni intrappolati nel FG, e i dati si cancellano.
Effettivamente, il passare degli elettroni attraverso lo strato di ossido (per uscirne) secondo le regole della meccanica classica sarebbe impensabile, ma in questo caso entra in gioco la meccanica quantistica, che ci dice (essenzialmente) che le possibilità di una particella di “bucare” un campo energetico superiore allʼenergia totale della particella medesima sono differenti da 0.
Le memorie flash sono molto veloci in lettura (quasi al pari delle RAM), mentre in scrittura risultano pessime.
A tutto ciò, va aggiunto che il tempo medio di vita di una memoria flash è risibile rispetto da una generica RAM.
Iniettando e togliendo costantemente elettroni infatti, a lungo andare (dopo un certo numero di cicli) si modifica permanentemente il drogaggio dei diodi tunnel che permettono il funzionamento della tecnologia.
Nello specifico, le lacune degli strati P tendono a riempirsi di elettroni, smettendo di essere lacune.
Per la loro instabilità, per la loro lentezza in scrittura e anche per il costo non proprio così abissale rispetto ad una generica RAM, non hanno preso il posto di queste ultime come memorie principali.
Di memorie RAM invece ne abbiamo diversi tipi, sono cambiate molto nel corso degli anni e cambiano continuamente anche ora, di solito ogni sei mesi (miglioramenti minimi, diciamo quasi sempre di aggiornamento di frequenza per adattarsi ai nuovi processori).
Le memorie ROM invece, seguendo la piena accezione del loro acronimo (Read Only Memory, memoria di sola lettura) si scrivono una volta sola (solitamente lo fa lʼindustria produttrice) e poi ogni successiva modifica è proibita.
Sono memorie che, generalmente, devono contenere istruzioni fondamentali al funzionamento di una risorsa hardware generica, la cui modifica da parte dell'utente sarebbe estremamente pericolosa.
È il caso, ad esempio, del firmware di una CPU, ovvero il programma che regola le funzioni basilari della stessa.
L'epoca del touch e le nuove interfaccie grafiche mobili

Il touchpad (o trackpad), implementato in un calcolatore portatile laptop
Nel 1986, il più grande ingegnere elettronico del 1900 e padre del primo microprocessore della storia, l'italiano Federico Faggin, decise di lasciare la famosissima Zilog, da lui stesso fondata e casa madre dello storico processore Z80 (a tutt'oggi ancora ampiamente usato), per fondare la rivoluzionaria Synaptics.
Tale azienda comincerà a sviluppare e ad introdurre per le masse un concetto rivoluzionario, proveniente sempre dall'assoluto genio di Faggin: un nuovo modo di interagire con le apparecchiature elettroniche, basato sul tocco umano.
Sul finire degli anni '80 e con l'inizio degli anni '90, il touchpad (chiamato anche trackpad, o tappetino tattile in italiano) progettato da Faggin diventerà lo standard per i dispositivi elettronici mobili, in particolare laptop, ma che verrà presto assorbito dall'industria telefonica, ed implementato nei telefoni cellulari.
Tale dispositivo segnerà l'inizio della rivoluzione tattile, che raggiungerà il suo apice con l'avvento dei primi smartphone negli anni 2000, e che diverrà lo standard della nuova informatica, tutta puntata essenzialmente alla mobilità e al facile utilizzo, che aprirà il nuovo millennio.
Con lo spostamento dei gusti delle utenze e dell'interfaccia fisica di connessione, sempre più tattile, sono cambiate anche le GUI dei Sistemi Operativi che, giocoforza, hanno dovuto adattarsi alle nuove esigenze.
iOS, all'epoca chiamato iPhone OS, nella sua prima versione
L'avvento dell'iPhone, con la prima versione di iOS, ha radicalmente cambiato il concetto stesso di interfaccia grafica: il File Manager si è sempre di più compattato, eliminando quanto più possibile di superfluo, per permettere una gestione agevole anche su display portatili, in cui lo spazio risolutivo disponibile è sempre enormemente più limitato che sui monitor da scrivania.
Ancora, file, cartelle ed applicazioni hanno subito una radicale rivisitazione, diventando sempre più elementi integrati in un Sistema a sua volta integrato nel cloud computing, quindi virtualmente espandibile all'infinito.
La modularità, sempre presente in qualsiasi contesto informatico, ha raggiunto la piena completezza, in un mercato che vede gli utenti cambiare dispositivi anche più volte nel corso di un anno, restando sempre attenti però a conservare le informazioni, che devono essere agevolmente trasferite tra un dispositivo e l'altro.
La portabilità delle informazioni, quindi, e l'importanza che ricopre nell'informatica attuale, ha ampiamente superato l'effettiva potenza di calcolo, un tempo parametro indiscusso di giudizio per qualsiasi dispositivo elettronico atto a far da calcolatore.
Possiamo aiutarti?
Sperimenti problemi col tuo iPhone, iPod, iPad o Mac, e vuoi affidarti a dei professionisti?
Siamo qui per ascoltarti ed aiutarti.
Offriamo solamente servizio in loco in tutta Milano, non abbiamo una sede fisica: ciò ci permette di risparmiare sui costi e garantire prezzi e tempi d'intervento eccezionali!
Compila il modulo qui sotto per metterti in contatto con uno dei nostri tecnici.
I nostri operatori vi aspettano, chiamateci!

Abbiamo i prezzi più bassi del mercato, ma non rinunciamo mai alla qualità.
Ovviamente, montiamo anche tutto ciò che il cliente vuole che sia montato, ma se dobbiamo fornire noi i ricambi harware, quali SSD e RAM, scegliamo sempre la qualità delle grandi marche, quali (solo a titolo esemplificativo) Corsair, Samsung e Seagate.
